We all want rivers that are safe to swim in, clean water to drink, and healthy freshwater ecosystems. However, many areas in New Zealand are not meeting our communities’ expectations and require improvement.1 Knowing where to target efforts to improve water quality is crucial, and a solid understanding of pressures is needed.
For management actions to be effective, they should be based on predictive relationships between land use, stressor levels in receiving waters, and the ecological and cultural responses to these stressors.2 Land use intensity is consistently identified as a key pressure on water quality in New Zealand. In both process-based and statistical models predicting water quality, land use is a significant predictor of E. coli and nitrogen concentrations.
For example, in NIWA’s recent random forest modelling of river water quality3, the top ten most important predictors of nitrate + nitrite-nitrogen (NNN) and E. coli were:
Predictor rank
NNN predictors
E. coli predictors
1
Stock density
Catchment elevation
2
Proportion of total stock units that are dairy
Rainfall variability
3
Proportion of total stock units that are Beef
Stock density
4
Intensive agriculture land cover
Bare land cover
5
Urban land cover
Intensive agriculture land cover
6
Catchment slope
Slope
7
Temperature Minimum
Urban land cover
8
Rainfall variability
Exotic forest land cover
9
Number of warm days
Local elevation
10
Catchment elevation
Catchment phosphorus
2 Aims
In this analysis, I aim to identify which areas of New Zealand have relatively high or low levels of contamination given relatively high or low livestock density. This is well-suited for visualisation using a bivariate colour scale.
Of course, this will be an exploration of just one of many interacting pressures determining the state of water quality. This technique allows exploring two variables at once, but trivariate maps would be almost impossible to interpret!
library(tidyverse)library(sf)library(mapview)library(koordinatr)library(biscale)library(cowplot)library(patchwork)library(ggtext)custom_pal4 <-c("1-1"="#f2f2f2", # low x, low y #ffffff"2-1"="#b9ddff","3-1"="#64bbff","4-1"="#0295ff", # high x, low y"1-2"="#fedcb7","2-2"="#b8b8b8","3-2"="#6691bb","4-2"="#0069ba","1-3"="#ffb869","2-3"="#b89168","3-3"="#676767","4-3"="#003867","1-4"="#ff9400", # low x, high y"2-4"="#bb6800","3-4"="#693800","4-4"="#000000"# high x, high y)
3 A Primer on Bivariate Maps
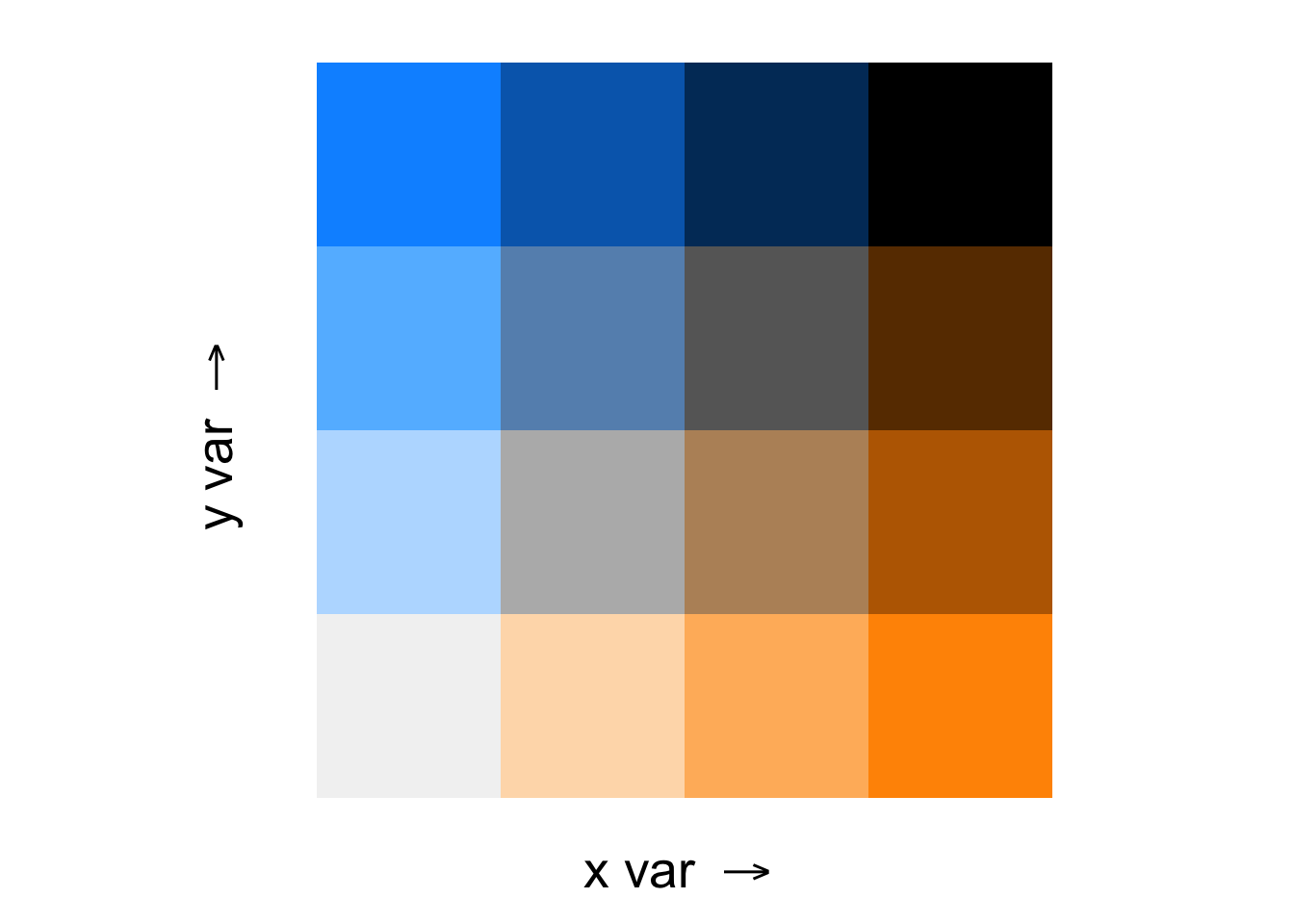
Figure 1: Example of bivariate colour scale grid.
Bivariate colour scale maps are thematic maps that use two different colour scales to simultaneously display two variables on the same map. This approach allows for the visualisation of the relationship between the two variables across a geographic space. Each colour on the map represents a unique combination of the two variables’ values.
Typically, one colour gradient is represented on the x-axis and the other on the y-axis. The intersection of these gradients results in a grid of colours, each representing a different combination of the two variables’ values (Figure 1).
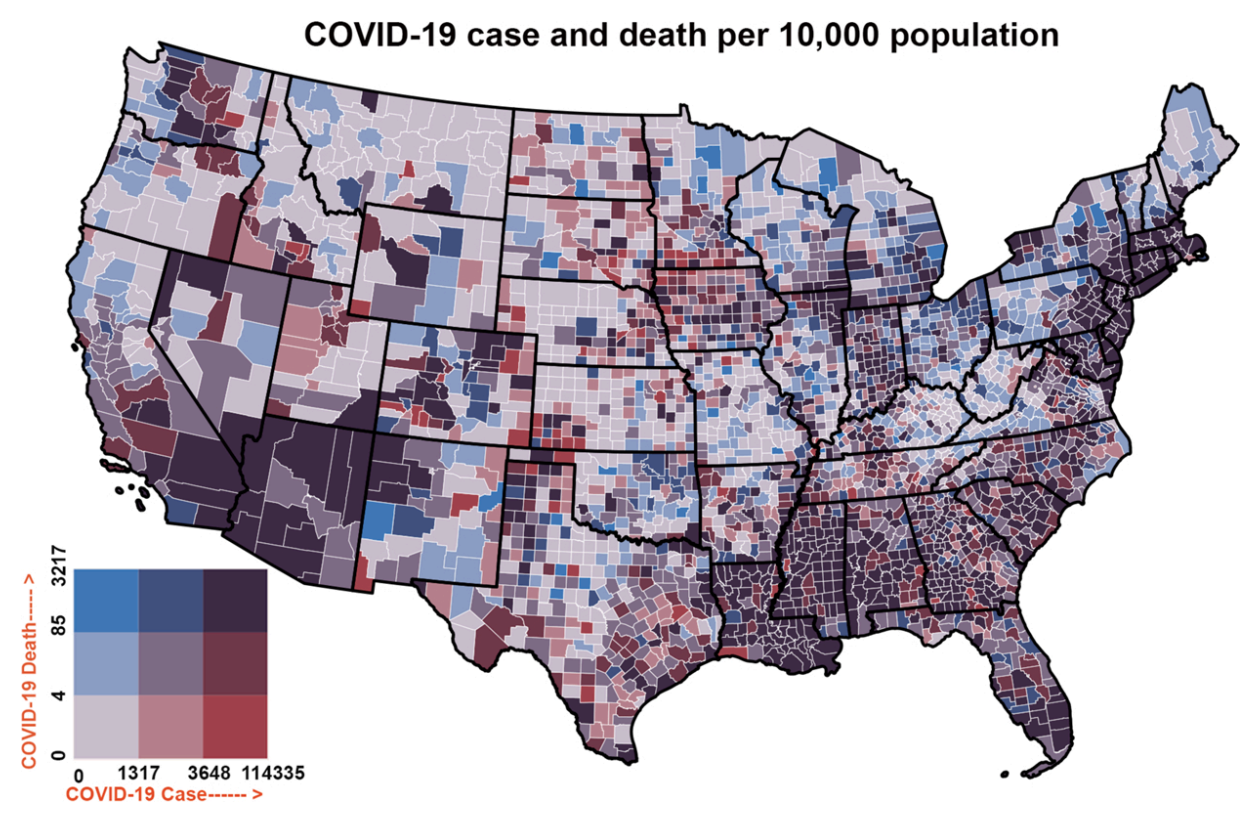
For example, here’s a bivariate map of COVID-19 case and death rates in the USA (Figure 2).4
Figure 2: Bivariate choropleth map demonstrates the county wise distribution (per 10,000 population) of COVID-19 cases and deaths from January 22 to July 26, 2020. From Maiti et al. 2021.
You can get a large amount of information from just this one map; you can see areas that had both low cases and death rates (doing very well), you can see areas that had an unexpectedly large number of deaths given a low number of cases (doing very poorly), you can see areas that had an unexpectedly low number of deaths given a high number of cases (doing quite well), etc.
But I’m interested in applying this to explore the relationship between livestock density and water quality.
4 Livestock vs Water Quality
4.1 Data sources
The data for stocking density, E. coli, and nitrogen (NNN) were obtained from the NIWA’s latest report on spatial modelling of river water quality in New Zealand. This report utilised monitoring data from 2016 to 2020 to develop model-based predictions for approximately 590,000 unique river segments across the national river network.
The study utilised random forest models to predict water quality state. This method involves using an ensemble of regression trees to improve prediction accuracy and handle complex, non-linear relationships between predictors and response variables.
Selected data used in this analysis includes:
Stocking Density: Represented as the number of livestock units per hectare. Derived from the Agricultural Production Survey hex grids.
E. coli: Modelled concentrations measured in colony-forming units per 100 millilitres (cfu/100ml). E. coli serves as an indicator of faecal contamination in water bodies.
Nitrogen: Modelled NNN concentrations measured in milligrams per litre (mg/L). Nitrogen levels are indicative of nutrient pollution, primarily from agricultural runoff.
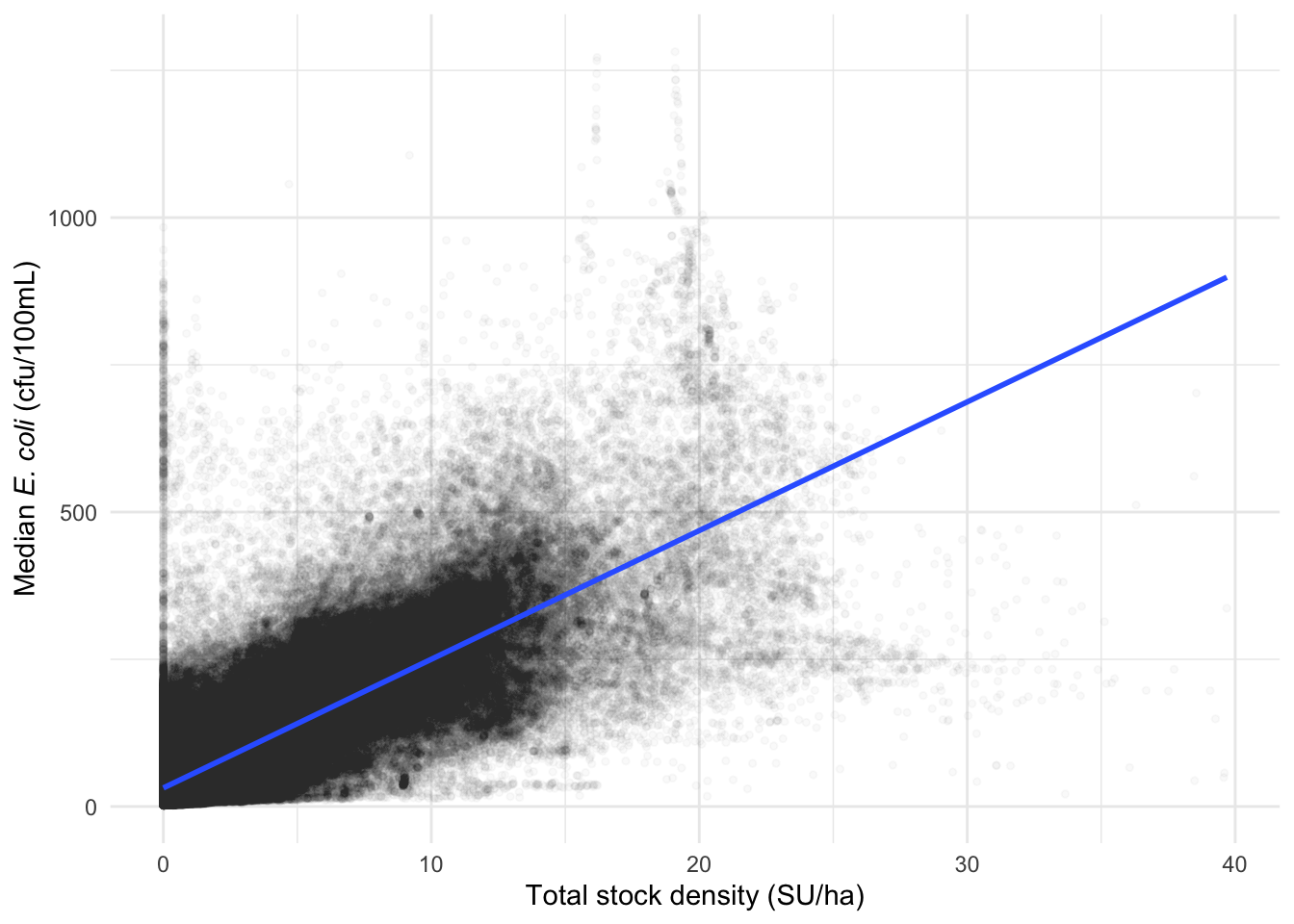
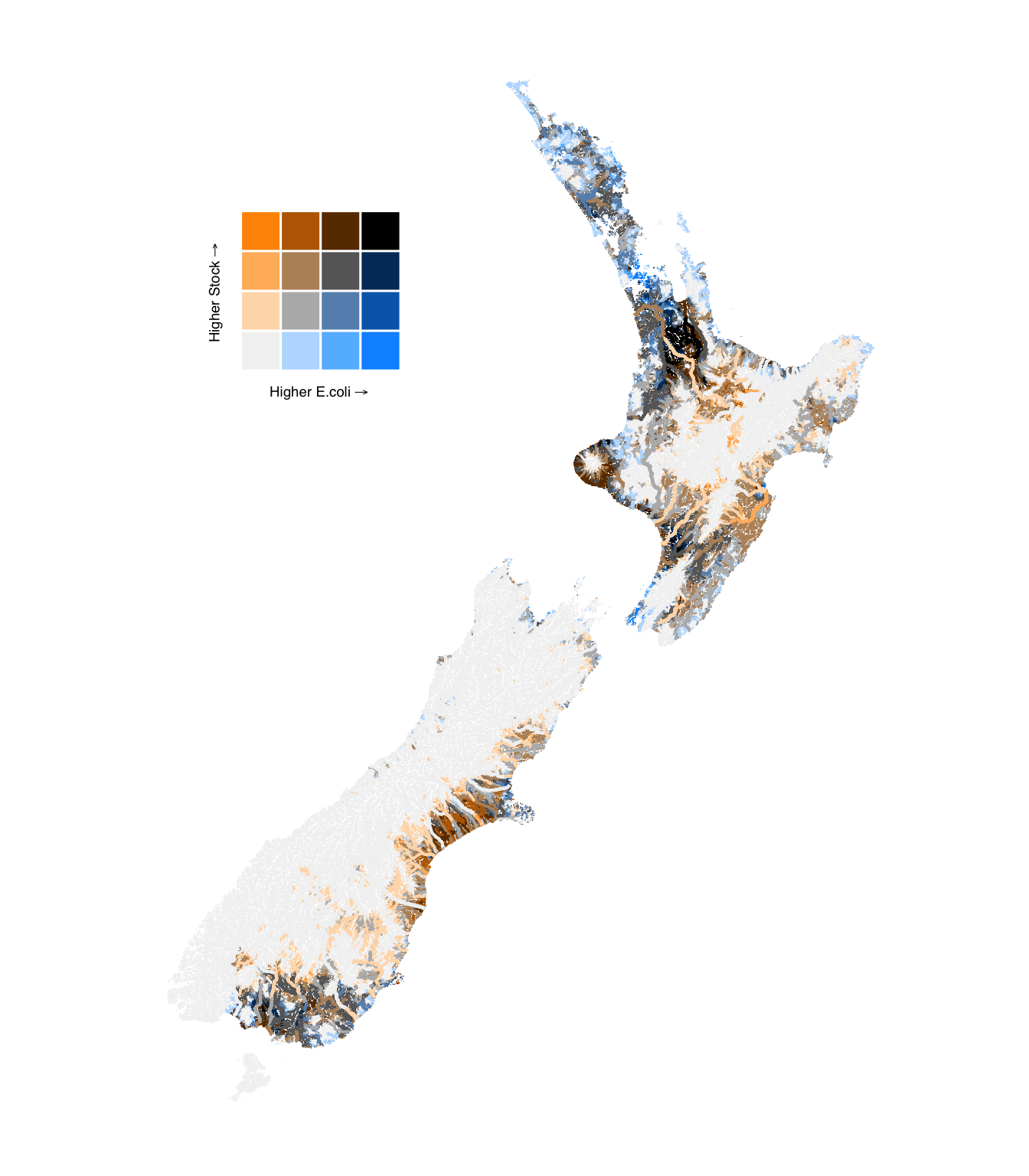
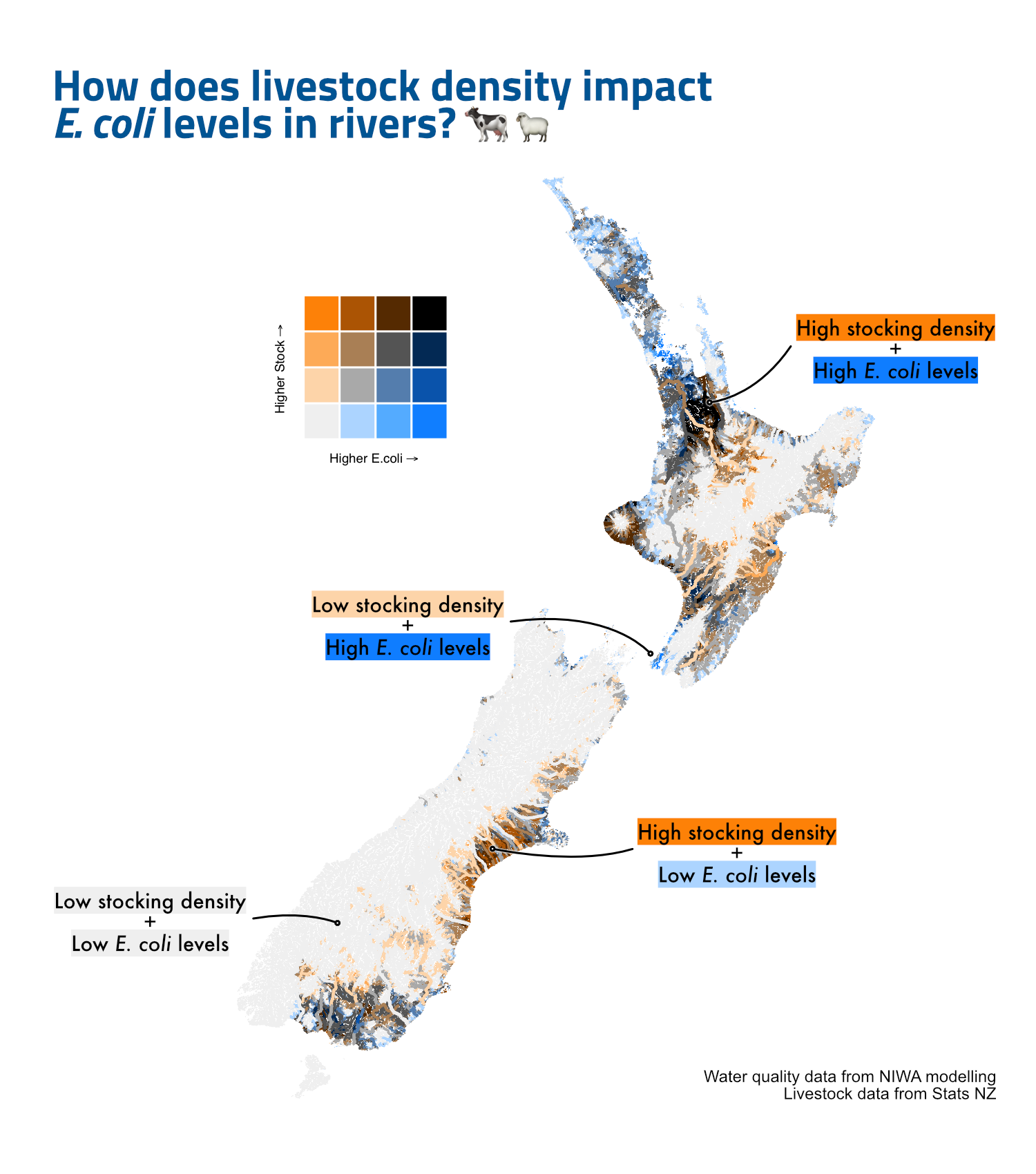
Let’s start by looking at the relationship between total stock density and median E. coli levels. There is a positive relationship between the two variables: areas with higher stock density tend to have higher E. coli levels (Figure 3).
However, the relationship is not perfect. Some areas have high stock density and low E. coli levels, and vice versa. This is where bivariate maps come in, allowing us to visualise the relationship between two variables across a geographic space.
Show the code
dat |>ggplot(aes(SUDensityTotal_2017, median_ecoli)) +geom_point(alpha =0.01, size =1) +geom_smooth(method ="lm") +theme_minimal() +theme(axis.title.y =element_markdown(),axis.title.x =element_markdown()) +labs(x ="Total stock density (SU/ha)", y ="Median *E. coli* (cfu/100mL)")
Figure 3: Scatter plot of total stock density and modelled median E. coli levels in river segments.
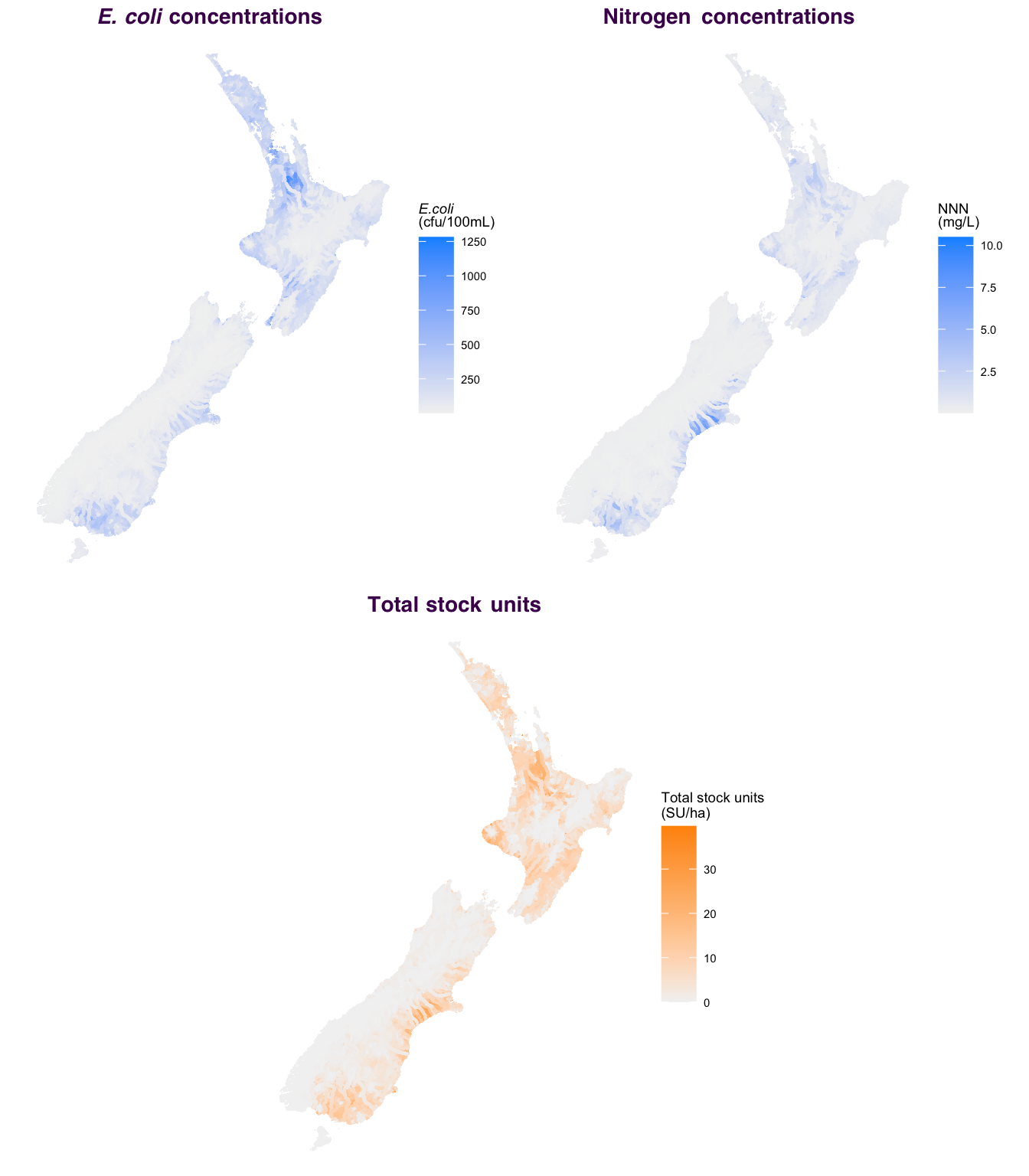
4.3 Univariate maps
Traditional maps use just a single colour scale to display a single variable (Figure 4). Displaying them side by side isn’t a bad option, but it’s challenging to compare locations with high stock density and low E. coli or nitrogen (and vice versa). Bivariate maps address this challenge.
Show univariate code
dat |>arrange(StreamOrder) |>ggplot() +geom_sf(aes(colour = median_ecoli, linewidth =log(StreamOrder)), show.legend =c(colour =TRUE, linewidth =FALSE)) +scale_linewidth_continuous(range =c(0.1, 0.8)) +scale_colour_gradient(low ="#f2f2f2", high ="#0295ff") +theme_void(base_size =7) +theme(plot.title =element_markdown(family ="sans", size =rel(1.5), face ="bold", color ="#4b015b", hjust =0.5),legend.title =element_markdown() ) +labs(title ="*E. coli* concentrations",colour ="*E.coli*<br>(cfu/100mL)" ) -> ecoli_mapdat |>arrange(StreamOrder) |>ggplot() +geom_sf(aes(colour = median_nitrogen, linewidth =log(StreamOrder)), show.legend =c(colour =TRUE, linewidth =FALSE)) +scale_linewidth_continuous(range =c(0.1, 0.8)) +scale_colour_gradient(low ="#f2f2f2", high ="#0295ff") +theme_void(base_size =7) +theme(plot.title =element_markdown(family ="sans", size =rel(1.5), face ="bold", color ="#4b015b", hjust =0.5),legend.title =element_markdown() ) +labs(title ="Nitrogen concentrations",colour ="NNN<br>(mg/L)" ) -> nnn_mapdat |>arrange(StreamOrder) |>ggplot() +geom_sf(aes(colour = SUDensityTotal_2017, linewidth =log(StreamOrder)), show.legend =c(colour =TRUE, linewidth =FALSE)) +scale_linewidth_continuous(range =c(0.1, 0.8)) +scale_colour_gradient(low ="#f2f2f2", high ="#ff9400") +theme_void(base_size =7) +theme(plot.title =element_markdown(family ="sans", size =rel(1.5), face ="bold", color ="#4b015b", hjust =0.5 )) +labs(title ="Total stock units",colour ="Total stock units \n(SU/ha)" ) -> dairy_dens_map# Arrange the plots using cowplottop_row <-plot_grid(ecoli_map, nnn_map, ncol =2)bottom_row <-plot_grid(dairy_dens_map, ncol =1)# Combine top and bottom rowscombined_plot <-plot_grid(top_row, bottom_row, ncol =1, rel_heights =c(1, 1))# Print the combined plotprint(combined_plot)
Figure 4: Univariate maps of modelled median E. coli, nitrogen levels in river segments and upstream stock density.
4.4 Bivariate colour scale maps
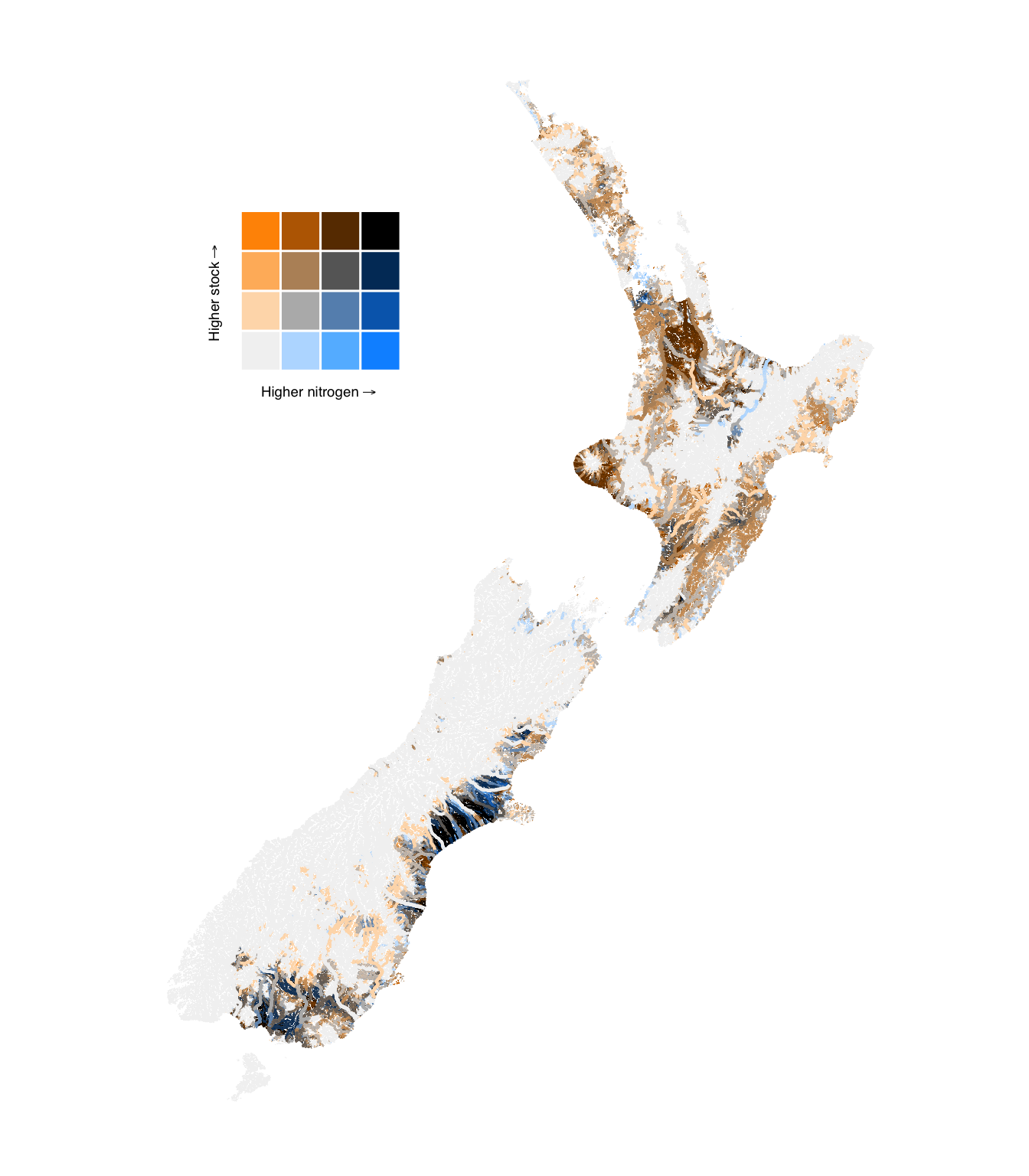
In these bivariate maps, we use two intersecting colour scales to represent two variables on a single map. The colour scale is divided into four quadrants, each representing a combination of high and low values of the two variables.
Remembering from above that total livestock density is “the catchment density of total stock units (SU) on pastoral land”, i.e. the density of all the livestock types on all the land upstream of the relevant river segment (where the water quality is also modelled).
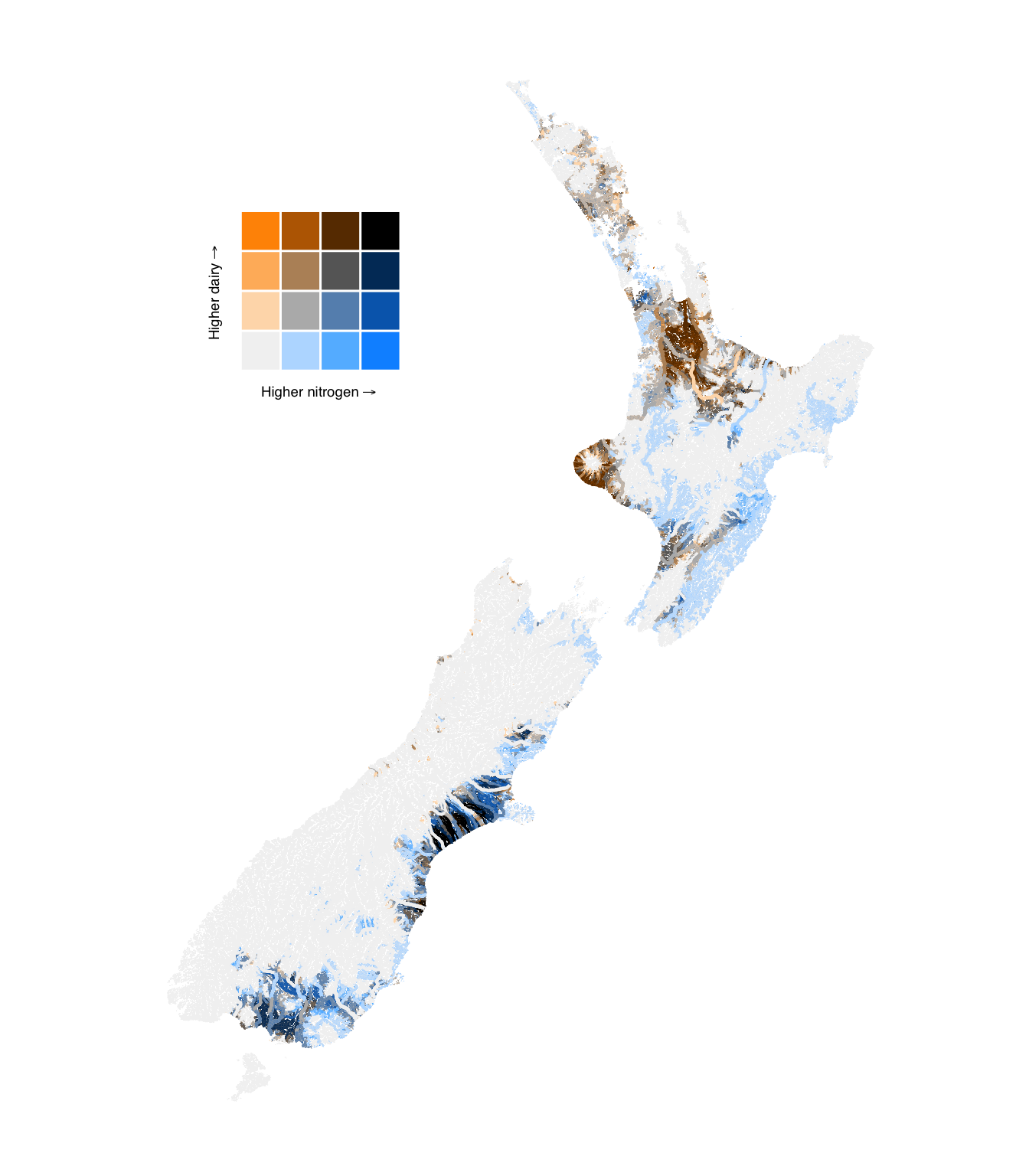
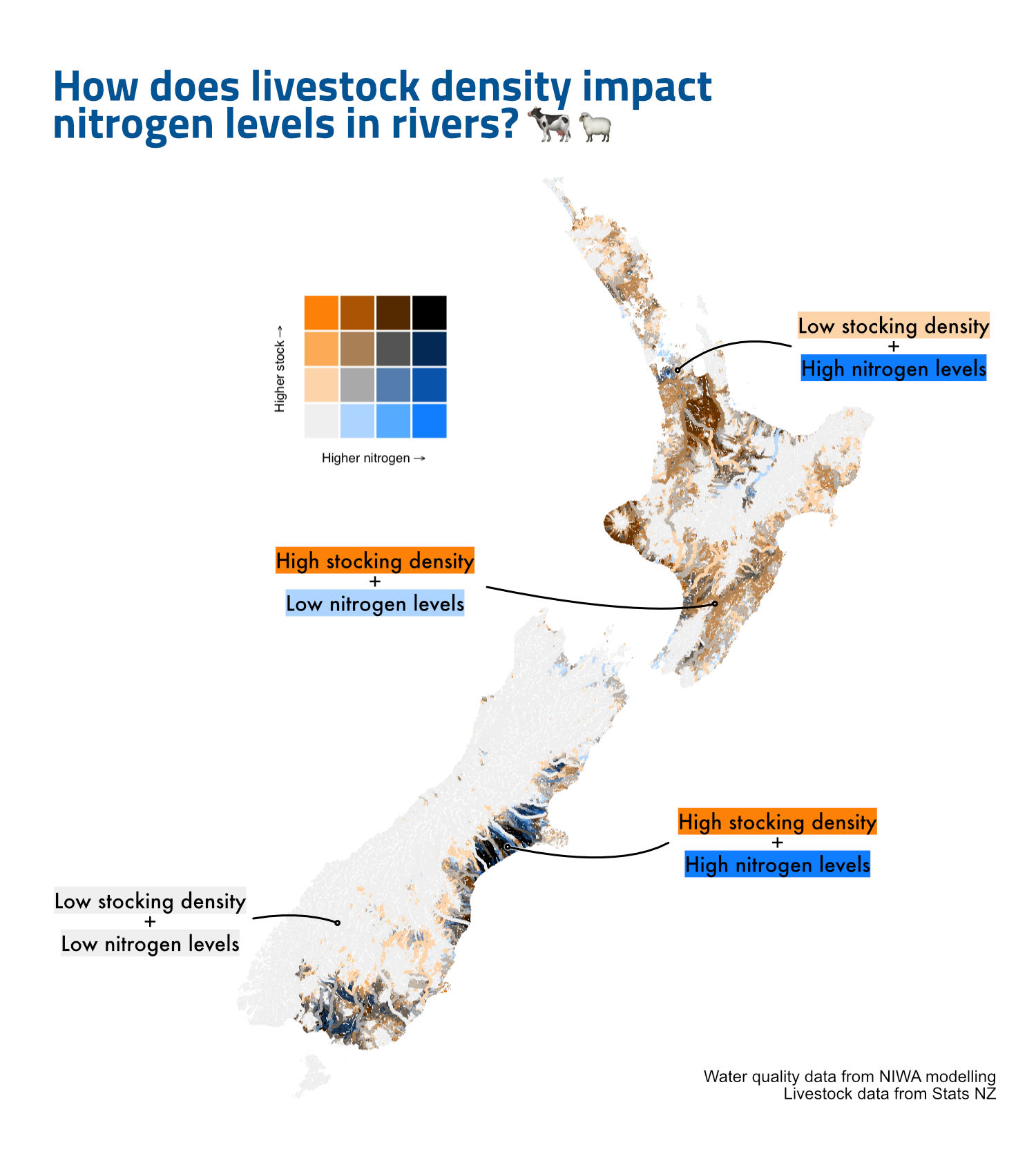
Figure 6: Bivariate maps of modelled median nitrogen levels in river segments and total upstream stock density.
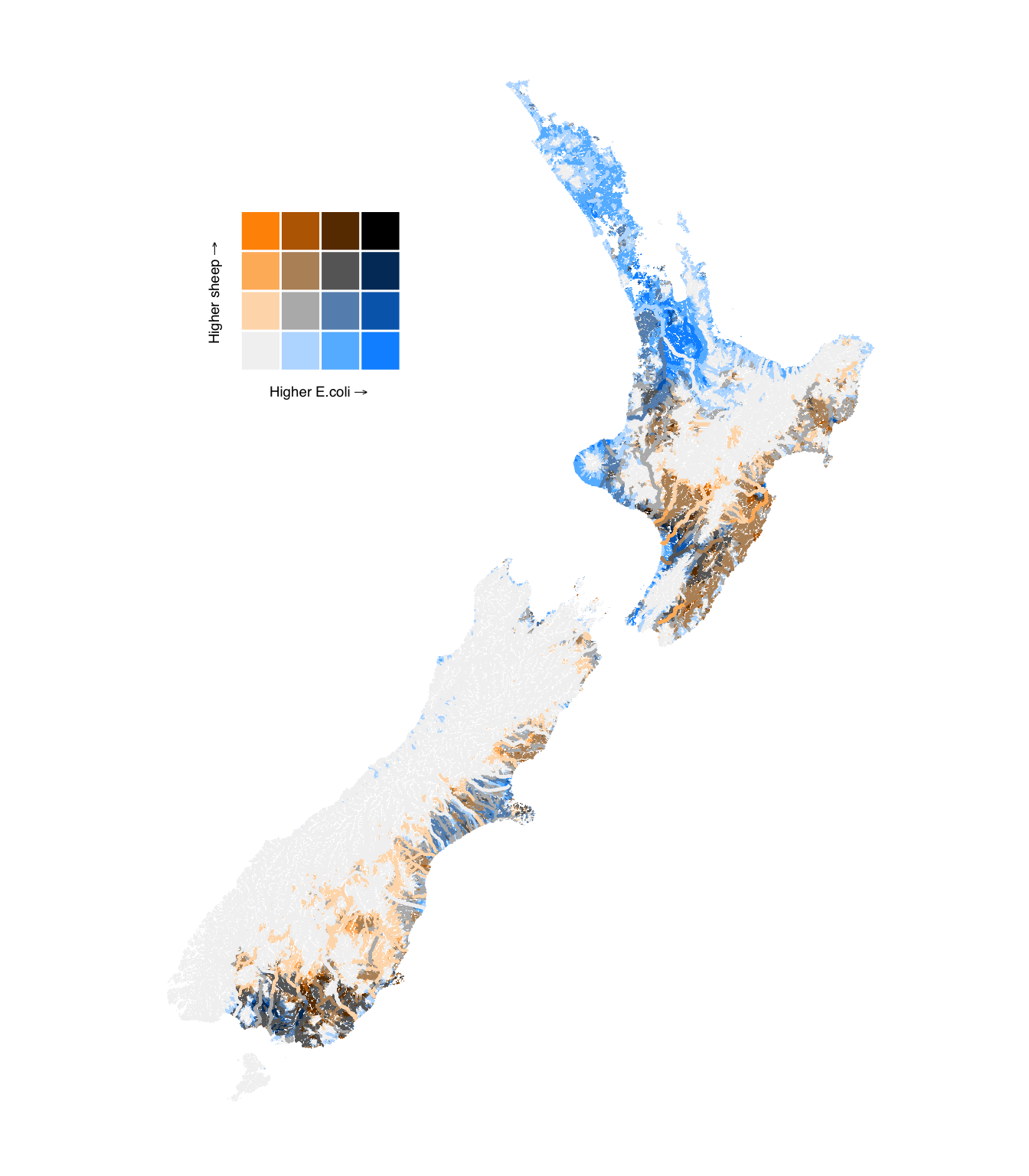
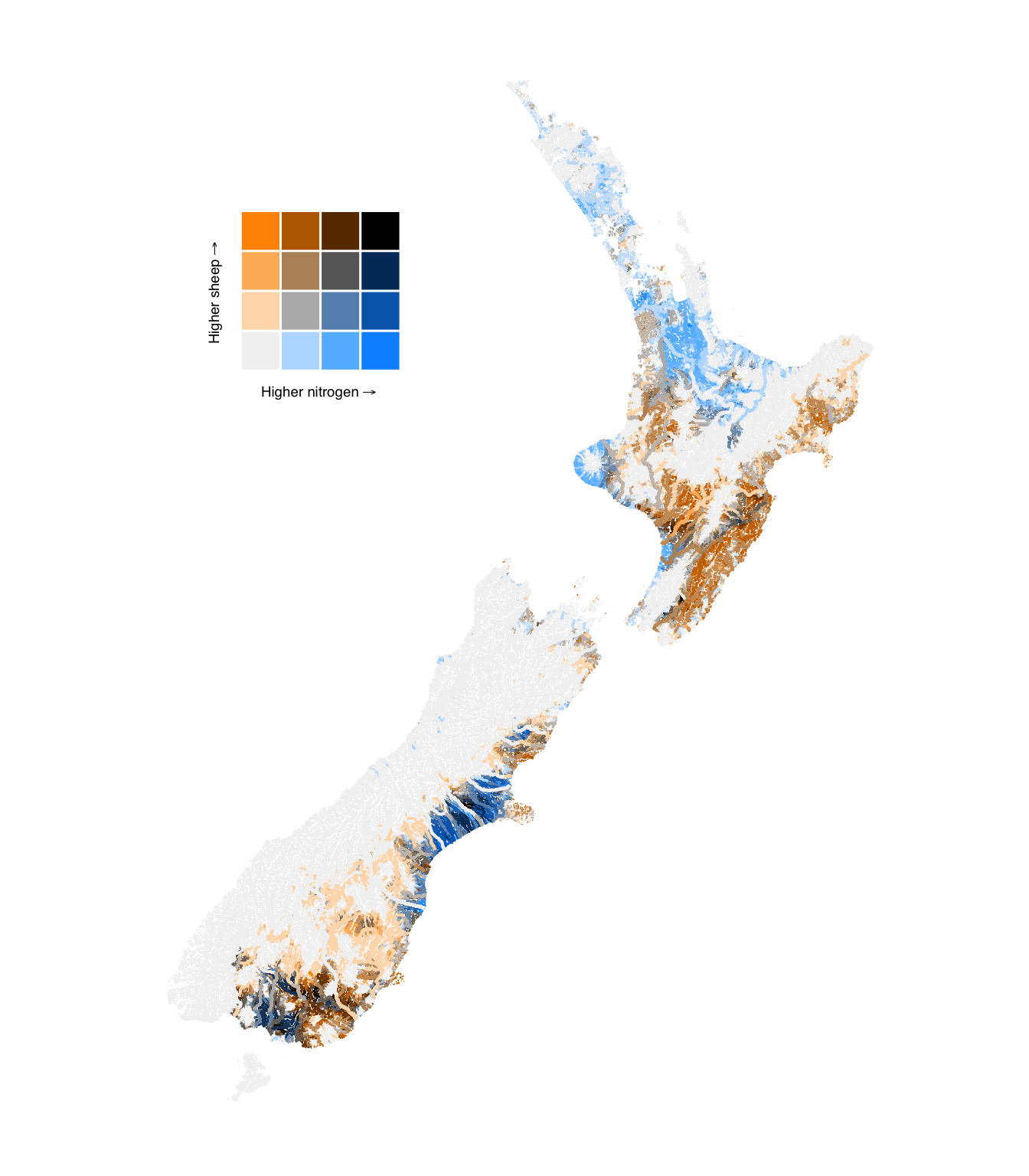
4.4.2 Sheep density
We can also separate the total stock density predictor into specific livestock types to see if the patterns differ for different types of livestock. Here, we show the results for sheep density.
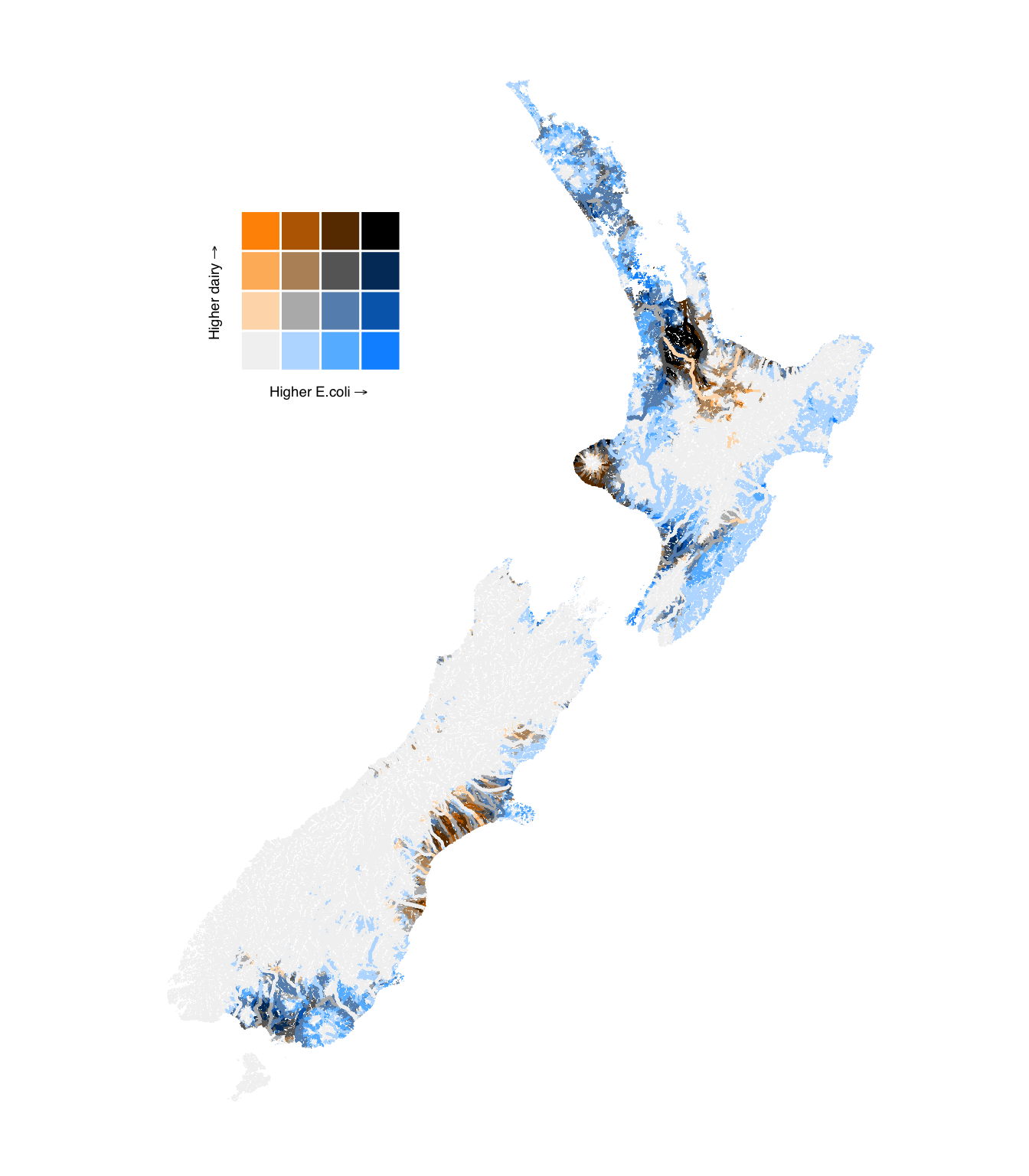
Canterbury, Waikato, Taranaki, and some areas of Southland have both high levels of dairy density and E. coli.
Canterbury has high levels of dairy density throughout the plain-fed rivers, but lower levels of E. coli in some rivers, due to the large alpine-fed systems.
Areas of the North Island outside of Waikato and Taranaki have relatively lower E. coli levels for a given dairy density.
Figure 10: Bivariate maps of modelled median nitrogen levels in river segments and upstream dairy density.
5 Conclusions
This analysis highlights the complex relationship between livestock density and water quality in New Zealand, for both E. coli (Figure 11) and nitrogen (Figure 12). Using bivariate colour scale maps, we can visually explore these interactions and identify regions where specific patterns emerge.
This analysis only covered two water quality indicators, but the same approach can be used for other indicators, such as phosphorus or sediment. Likewise, livestock density is only one of many predictors that can be used to model water quality. Other predictors, such as urban land use, climate, and topography, can also be visualised in similar way to provide a more comprehensive understanding of the relationship between livestock density and water quality.
Figure 11: Bivariate comparison of upstream livestock density and modelled E. coli concentration in river segments.
Figure 12: Bivariate comparison of upstream livestock density and modelled nitrogen concentration in river segments.
Scott T. Larned, Jonathan Moores, Jenni Gadd, Brenda Baillie & Marc Schallenberg (2020) Evidence for the effects of land use on freshwater ecosystems in New Zealand, New Zealand Journal of Marine and Freshwater Research, 54:3, 551-591, DOI: 10.1080/00288330.2019.1695634↩︎
Snelder T. H., Fraser C., Larned S. T., Monaghan R., De Malmanche S., Whitehead A. L. (2022) Attribution of river water-quality trends to agricultural land use and climate variability in New Zealand. Marine and Freshwater Research 73, 1-19.↩︎
Maiti, Arabinda & Zhang, Qi & Sannigrahi, Srikanta & Pramanik, Suvamoy & Chakraborti, Suman & Cerdà, Artemi & Pilla, Francesco. (2021). Exploring spatiotemporal effects of the driving factors on COVID-19 incidences in the contiguous United States. Sustainable Cities and Society. 68. 102784.↩︎