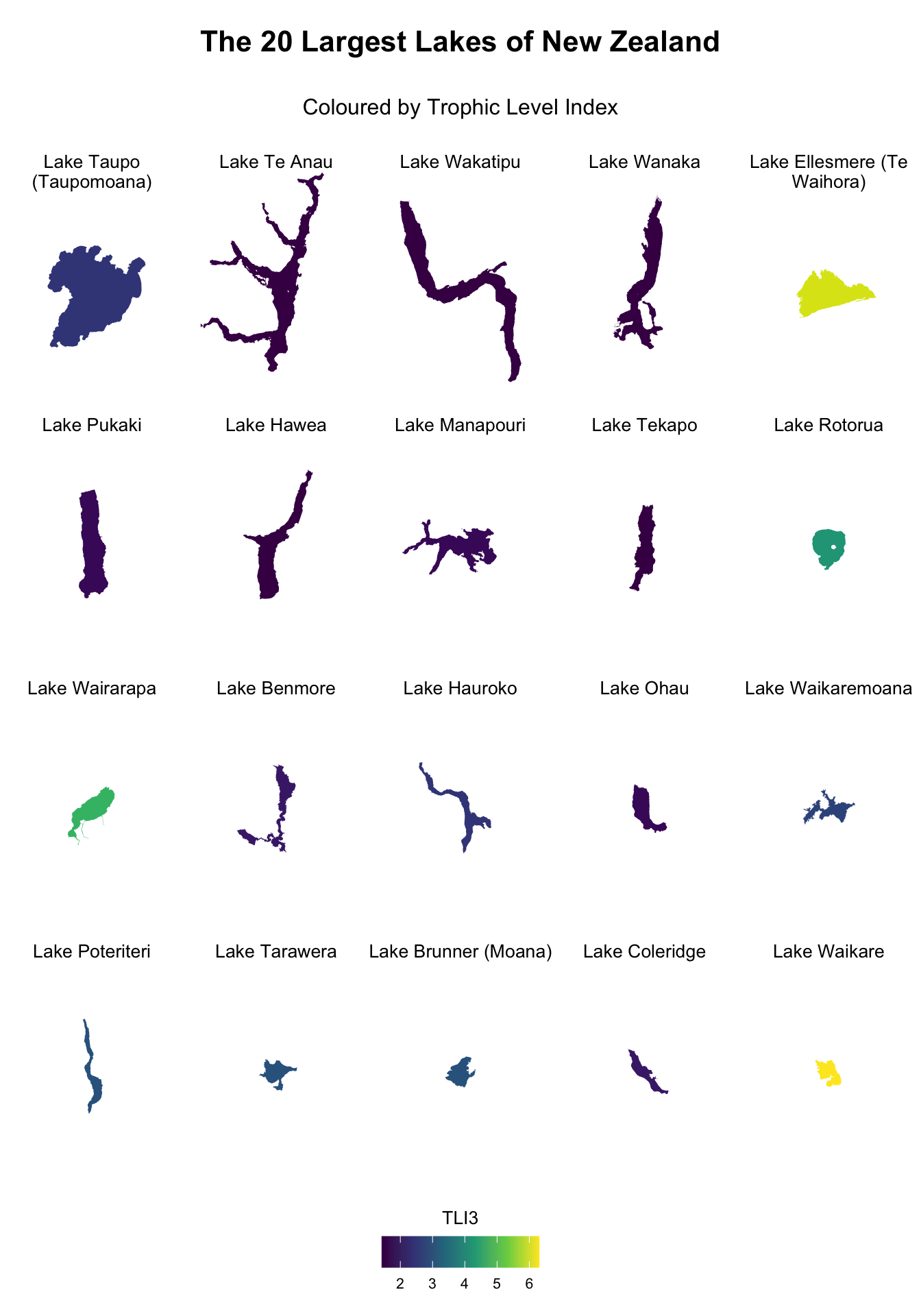
I’ve been inspired by a new type of small multiples map I’ve seen, where multipolygons are extracted from their spatial locations and reassembled in a grid while maintaining their relative sizes. If you unsure what I mean, check out this one as an example. So I thought I’d try applying it to some lakes data in New Zealand.
1 Libraries and import data
The Department of Conservation’s Freshwater Ecosystems of New Zealand (FENZ) geodatabase provided the lake boundary polygons. While one could also source these from the LINZ topo map layers, the advantage of the FENZ layer is that it can be linked to other datasets, such as modelled water quality.
The Ministry for the Environment provides modelled lake water quality data for 3,813 lakes in New Zealand that are larger than 1 hectare. This data can be joined using the FENZ lake ID. The dataset is generated by a statistical learning model (specifically, a random forest model) trained on actual monitoring data and using a number of environmental predictors to extrapolate out to unmeasured lakes.
Sorting the lakes dataset by size (surface area) and selecting the largest ones is a fairly straightforward task. Interestingly, there is a discrepancy between my data and this Wikipedia page listing the sizes of lakes in NZ. Wikipedia lists it as 141 km2, whereas my data shows it as 152 km2. Since the Wikipedia article does not list its sources, the origin of this discrepancy remains unclear!1
I’ve have also selected Trophic Level Index (TLI) as an indicator of water quality - more on that below.
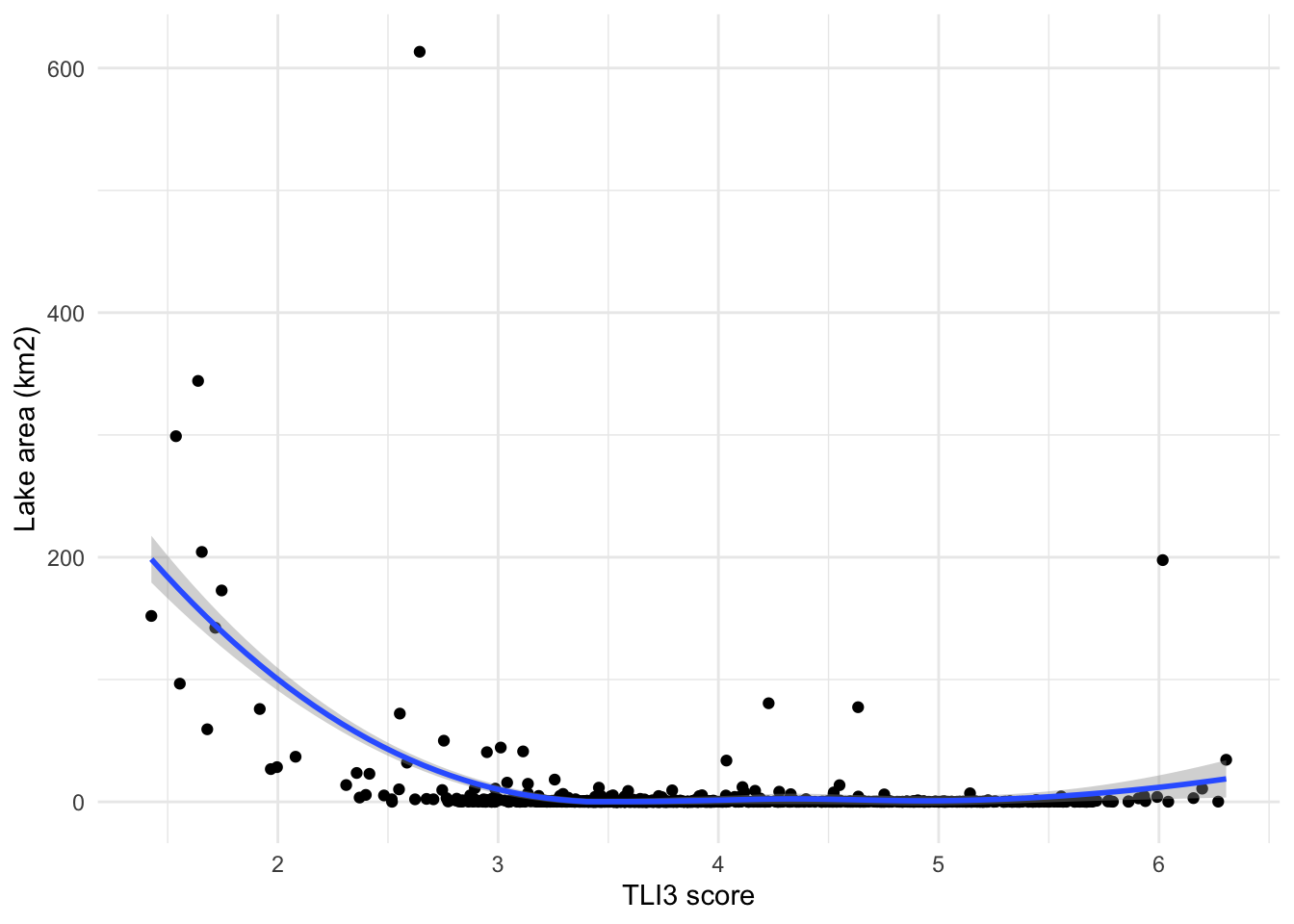
There’s an interesting pattern regarding lake size and water quality. None of the lakes with very low values of TLI3 (e.g <2) are small. This could just be an artifact of the modelled data, perhaps a relationship that the model has learned incorrectly due to a strong bias in the training data. It would be better to using monitoring data here to confirm this relationship.
Now, let’s get down to plotting the largest lakes, and colour them by their respective TLI3 score. LAWA provides a good fact sheet on what this metric means. In short:
The Trophic Level Index (TLI) is a method of characterising the ecological health of lakes based on the amount of nutrients and algae growing in them. It provides an integrated measure of water quality that can be tracked over time and that can be used to estimate biological productivity. It is presented as a score, the lower the score the better the condition of the lake.
Here’s what the scores correspond to in ecological terms:
TLI Score
Description
0–2
Microtrophic: The lake is very clean with very low levels of nutrients and algae. The lake can have snow or glacial sources.
>2–3
Oligotrophic: The lake is clear and blue, with low levels of nutrients and algae.
>3–4
Mesotrophic: The lake has moderate levels of nutrients and algae.
>4–5
Eutrophic: The lake is murky, with high amounts of nutrients and algae.
>5
Supertrophic: The lake has very high amounts of phosphorus and nitrogen, and can be overly fertile and often associated with poor water clarity. Excessive algae growth can occur. Suitability for recreational purposes is often poor.
Show the code
# Calculate centroidslake_polygons <- lakes_20 %>%mutate(centroid =st_centroid(st_geometry(.)))# Sort the lake polygons by shape_area in descending orderlake_polygons <- lake_polygons %>%arrange(desc(shape_area))# Compute bounding boxes and find the maximum width and heightbboxes <-lapply(st_geometry(lake_polygons), function(x) as.numeric(st_bbox(x)))max_width <-max(sapply(bboxes, function(x) abs(x[1] - x[3])))max_height <-max(sapply(bboxes, function(x) abs(x[2] - x[4])))# Set padding to ensure polygons are not cut offpadding <-3500# Adjust this value based on your specific spatial scale# Calculate colors based on valuelake_polygons$color <- viridis::viridis(n =nrow(lake_polygons), option ="D", direction =1)[cut(lake_polygons$value, breaks =nrow(lake_polygons), labels =FALSE)]# Function to make plotsgraph <-function(x) { centroid <-st_coordinates(lake_polygons$centroid[x])ggplot(lake_polygons[x, ]) +geom_sf(fill = lake_polygons$color[x], colour =NA) +coord_sf(xlim =c(centroid[1] - max_width/2- padding, centroid[1] + max_width/2+ padding), ylim =c(centroid[2] - max_height/2- padding, centroid[2] + max_height/2+ padding), expand =FALSE) +theme_void() +ggtitle(str_wrap(lake_polygons$name[x], width =20)) +theme(plot.title =element_text(hjust =0.5, size =10, vjust =1),legend.position ="none")}# Create a list of plotsplot_list <-lapply(1:nrow(lake_polygons), FUN = graph)# Combine plots and titlescombined_list <-lapply(plot_list, function(p) { title <-ggplot_build(p)$layout$panel_params[[1]]$title gridExtra::arrangeGrob(p, top = grid::textGrob(label = title,gp = grid::gpar(fontsize =10),hjust =0.5,vjust =1 ))})# Create the overall title and subtitle grobsoverall_title <- grid::textGrob("The 20 Largest Lakes of New Zealand", gp = grid::gpar(fontsize =16, fontface ="bold"))subtitle <- grid::textGrob("Coloured by Trophic Level Index", gp = grid::gpar(fontsize =12))# Create a common legend plot to extract the legendlegend_plot <-ggplot(lake_polygons) +geom_sf(aes(fill = value), colour =NA) +scale_fill_viridis_c(name ="TLI3", option ="D", direction =1) +theme_void() +theme(legend.position ="bottom",legend.title =element_text(size =10, hjust =0.5),legend.title.position ="top",legend.text =element_text(size =8),legend.box.margin =margin(0, 0, 0, 0) )# Extract the legendlegend_grob <- cowplot::get_plot_component(legend_plot, 'guide-box-bottom', return_all =TRUE)# Arrange the plots together with the overall title and subtitlefinal_plot <- gridExtra::grid.arrange( gridExtra::arrangeGrob(overall_title, subtitle, ncol =1, heights =c(0.08, 0.05)),do.call(gridExtra::arrangeGrob, c(combined_list, ncol =5)), legend_grob,nrow =3,heights =c(0.1, 0.8, 0.1))
4 Plot the 50 largest lakes
Bonus just for the blog readers… here’s the plot for the 50 largest lakes in New Zealand!
5 Next steps
Plot the smallest 20 lakes
Make an estuaries small multiples map
Figure out how to shrink the rows for the smaller lakes